0 to Microservice in 5 minutes with Go and Minke
Introduction
I went to a conference a few weeks ago which was angled at technology in the retail environment, by lunchtime nobody had mentioned the words “Docker” or “Microservices”, I made my excuses and got the hell out of there. Everyone is talking about Microservices, even the bus driver the other day was complaining that the reason the bus was late was due to not enough monitoring in their scheduling microservice. Allegedly the wrong config was pushed to Consul, the service was failing and nobody knew. OK so the last part might be made up but I bet a few of you will have felt that pain, those who have not, don’t worry, when it happens it will be OK. Unless of course you work on nuclear missile launch systems and you accidental wipe out life for half the planet, that would not be OK, very not OK.
The thing is that everyone is talking about microservices but the frameworks and development practices are not so mature yet, there are some amazing companies like Netflix and USwitch who have been using this stuff for a number of years but knowledge and patterns have only slowly seeped out into the mainstream. Rails was not built in a day and it will be the same for a good microservice framework, there is some amazing stuff on the horizon but the key will be mass adoption and contribution.
What I would like to show you in this post is how you can go from 0 - Microservice in 5 minutes, that’s scaffolding a new service building and testing locally then getting the build and test passing on CI. I will assume that you have the Docker Toolkit, Ruby and Go installed on your dev machine as otherwise that might take longer than 5 minutes and that would mess with the title of my post.
Frameworks
I started to build my own framework when I was re-developing a project originally written in C#, I wanted something which was minimal and would cover 90% of my use cases, something which worked with my rather opinionated method of development and testing which is Google’s Go as my language, Cucumber and Ruby for my functional test suite, Docker stuff for my platform.
When I first started to build microservices in Go I found that I would repeat the same scaffolding steps time and time again. I would copy some boiler plate code for my functional tests and also for my build scripts. It all became a little unmanageable by the time I had finished the second service, I had also learned a lot. Thats when I first built go-microservice-template this worked really well for a while but I found that whilst it was fine to add the new learnings to the template it was a total pain to update existing services.
Time for split, go-microservice-template was put out to pasture and the build and test framework was split out into a separate Rubygem called Minke. With Minke I implemented the concept of Generators which would support scaffolding and building applications in multiple languages not just Go. So far this has worked well, localising my build and test code into a gem has recently proven useful when I switched from my own Jenkins server to CircleCI and found myself unable to use the Docker exec command. Being able to update a central gem saved hours and hours of copy and pasting.
Go Microservice Generator for Minke
Installing and scaffolding a microservice
Assuming your GOPATH is set correctly to get a copy of the template on your local computer and you have Ruby 2.x you need two gems installed:
$ gem install minke
$ gem install minke-generator-go
This will install the two gems into your gem cache, to generate your service you simply execute following command (obviously changing the paths unless your github user is nicholasjackson in which case you will be me).
$ minke -g minke-generator-go -o $GOPATH/src/github.com/nicholasjackson/hello -n github.com/nicholasjackson -a hello
The options for the above command are:
| flag | |
|---|---|
| -g | generator template to use |
| -o | output folder for generated code |
| -n | namespace for application |
| -a | application name |
The application will then scaffold the service for you and place the contents at:
$GOPATH/src/[your_namespace]/[service_name]
The service should be ready to build and deploy, complete with a couple of example endpoints, unit and functional tests.
Sprint 0
Scaffold the service and get it deploying to production. If I had pound for every time a project has been delayed due to the complexities (software and people) of getting a service deployed to production I would currently be surfing and not writing this post. I designed the template to be running and testable straight out of the box so that the next task can be to get it running in the continuous delivery pipeline.
I recommend that this is not only set up for Dev and Test environments but you build the pipeline into production. You do not need to expose the service but I certainly recommend deploying to production every time you commit to master as a matter of good practice.
A closer look at the scaffolded service?
As I mentioned earlier I am a fan of the Bauhaus approach to my scaffolding; clean lines and minimalist. There are however a few key things that I find I can not do without in every service.
- Dependency Injection - My current favorite is the Facebook inject package github.com/facebookgo/inject.
- Routing - Tried and tested it has to be Gorilla all the way github.com/gorilla
- Request Validation - As my friend Yan Ettles would say “Input Validation, Input Validation, Input Validation”, security is essential and this is a good place to start github.com/asaskevich/govalidator.
- Logging - Metrics are incredibly important, personally I like to use StatsD for simple metrics you can store these in a service like Datadog or if you need to host your own you can use Graphite and Carbon. For more detailed logs Syslogd will do the trick you can export your logs to either something like Loggly or your own ELK (Elasticsearch, Logstash, Kibana) stack.
Dependency Injection
The Facebook framework is excellent allowing you to inject:
- Shared instances of objects.
- Named instances of objects, useful when the framework can not infer from the type such as when using an interface.
- Private objects which are unique to each injected class.
This does not feel very Go like and there are a lot of question on why you need to use dependency injection in Go when you can just have a shared package which stores references. For me it is largely about the ugliness and brittleness of the code when using a shared package but also Facebook inject has some nice features like it will traverse a tree when creating an object, automatically creating and injecting sub dependencies. Take a look at handlers/health.go and handlers/health_test.go for an example of use, the initial graph creation takes place in the main startup method.
There is some weird code in the health handler which I must warn you about:
type HealthResponseBuilder struct {
statusMessage string
}
func (b *HealthResponseBuilder) SetStatusMessage(message string) *HealthResponseBuilder {
b.statusMessage = message
return b
}
func (b *HealthResponseBuilder) Build() HealthResponse {
var hr HealthResponse
hr.StatusMessage = b.statusMessage
return hr
}
type HealthDependenciesContainer struct {
// if not specified will create singleton
SingletonBuilder *HealthResponseBuilder `inject:""`
// statsD interface must use a name type as injection cannot infer ducktypes
Stats logging.StatsD `inject:"statsd"`
// if not specified in the graph will automatically create private instance
PrivateBuilder *HealthResponseBuilder `inject:"private"`
}
I generally would not write code like this for such a simple purpose it is purely as an example to myself as to what is possible with Facebook inject.
Routing
When it comes to routing I have used the Gorilla Toolkit since my first go application, it is fast and does everything I need. The handlers package deals with the routing and setting up a new handler with Gorilla is a breeze.
r.Get("/v1/health", HealthHandler)
r.Add("POST", "/v1/echo", requestValidationHandler(
ECHO_HANDLER+POST,
reflect.TypeOf(Echo{}),
RouterDependencies.StatsD,
http.HandlerFunc(EchoHandler),
))
We are using two different ways of registering a handler the simpler Get which takes a path and function and the more complex Add. The more complex option is so we can add some middleware before our handler gets called, this is where we perform our validation and what I will get on to next.
Request Validation
The go validator package github.com/asaskevich/govalidator is awesome, it allows us to use struct annotation to define what valid is for our properties and then by simply calling a method on the validator package we get an array of error messages and an error object if the validation fails.
type Echo struct {
Echo string `json:"echo" valid:"stringlength(1|255),required"`
}
request = Echo{}
request.Echo = "Valid String"
errors, err = govalidator.ValidateStruct(request)
When we wire up this code into middleware like in the requestValidationHandler we have the ability to ensure our routing goes through the middleware before the handler, this means we can implement painless request validation for every handler. govalidator has just about every possible scenario you could like to cover including some really nice things like validating a string as a url or net address all is explained in the package docs.
Logging
You need logging and I recommend lots and lots of metrics out via StatsD or something similar. There are various options from Gauges, Counters, Timing Summary Statistics, and Sets but whatever you use having the right data will not only help you debug and diagnose a problem but you can setup alerting in systems such as Datadog to wake you up in the middle of the night when something goes wrong, and believe me it will go wrong. The simple implementation in the template is just using Increment (Counter) but it is easy to add other measures if required. When you run the application Graphite is also spun up which is accessible at http://192.168.99.100:8080/ where 192.168.99.100 is the ip address of your docker machine.
I have also stated an opinion on a way to define the tags for the various metrics in const.go in the handlers package. Ideally you do not want to only create a common format for metric tags in your microservice but treat it like a coding standard. Stick to the same format for every service, it will make dashboard creation a thousand times easier and you will not have to spend a week refactoring all the tags across 20 microservices because they were difficult to understand.
package handlers
const GET = ".get"
const POST = ".post"
const CALLED = ".called"
const SUCCESS = ".success"
const BAD_REQUEST = ".bad_request"
const INVALID_REQUEST = ".invalid_request"
const VALID_REQUEST = ".valid_request"
const HEALTH_HANDLER = "helloworld.health_handler"
const ECHO_HANDLER = "helloworld.echo_handler"
Testing
Testing with go-microservice-template is broken into two groups:
- Unit tests (Go)
- Functional tests (Cucumber)
I follow an outside in methodology when writing code, this is my preference it works for me therefore my framework does this too. I did say this was an opinionated framework didn’t I?
Unit tests
The nice thing about Go is that you can test handlers independently from the HTTP server which allows you to tests the logic of your handler really quickly. Combine this with the dependency injection framework to isolate dependencies or inject mocks, you have a really efficient and fast way to do test driven development.
The below code is one of the tests, we are mocking the request and checking the response, since there is no HTTP server involved these tests are actually really fast to run. This gives us the ability to write full coverage on our handlers as well as other logic, the only bit not covered is the wiring of the router and the start of the service but this will get coverage from the functional tests.
func TestEchoHandlerCorrectlyEchosResponse(t *testing.T) {
echoTestSetup(t)
var responseRecorder *httptest.ResponseRecorder
var request http.Request
responseRecorder = httptest.NewRecorder()
echo := Echo{Echo: "Hello World"}
context.Set(&request, "request", &echo)
EchoHandler(responseRecorder, &request)
body := responseRecorder.Body.Bytes()
response := Echo{}
json.Unmarshal(body, &response)
assert.Equal(t, 200, responseRecorder.Code)
assert.Equal(t, response.Echo, "Hello World")
}
Functional tests
All the functional tests are in the _build/features folder and are written in Gherkin. Cucumber is my weapon of choice, Ruby and Rspec are just perfect for the job and there are quite a few cucumber plugins which have been developed meaning you need to write very few actual step implementations. Following this method you gain the ability to create some oh so essential integration tests and a really nice way to express the behavior of the service which defines the contract between you and the client.
Scenario: Echo returns same data as posted
Given I send a POST request to "/v1/echo" with the following
| echo | Hello World |
Then the response status should be "200"
And the JSON response should have "$..echo" with the text "Hello World"
By using a gem such as cucumber-rest-api the above cucumber feature will execute without needing a single step file (NOTE: version 0.4 of this gem is broken). That is not so difficult to maintain, all you cucumber haters complaining about your slow and brittle test suite already screaming NOOOO. I’m going to make a statement, you won’t like it and it will most likely fill my comments with hate but here goes anyway.
It’s not cucumber it’s you!
Test the behavior of your contract, a little integration and trust your unit tests to cover the rest, more often than not test coverage in functional tests is way too high. The other benefit of microservices are that your bloated test coverage will be distributed across multiple repos, instant test paralyzation.
Minke
Minke is an opinionated build system for Docker based microservices like go-microservice-template it encapsulates all the horrible boilerplate build scripts and wraps them up so you only need to deal with config files like the extract below. I will not go to much into depth with minke it is worth reading the readme at https://nicholasjackson.github.com/minke however we will look at the commands which build and test your microservice.
---
application_name: 'helloworld'
namespace: 'github.com/nicholasjackson'
generator_name: 'minke-generator-go'
docker_registry:
url: <%= ENV['DOCKER_REGISTRY_URL'] %>
user: <%= ENV['DOCKER_REGISTRY_USER'] %>
password: <%= ENV['DOCKER_REGISTRY_PASS'] %>
email: <%= ENV['DOCKER_REGISTRY_EMAIL'] %>
namespace: <%= ENV['DOCKER_NAMESPACE'] %>
Inside the _build folder is a Gemfile with all the Ruby dependencies in it like Minke, before we can build our service we need to install them, you need a Ruby interpreter, personally I recommend RVM to manage the different versions of Ruby and all the dependencies.
- Ensure Docker server is running and you have the docker environment variables set.
- Install the gems with
bundle install. - Build the service
rake app:build_imagethis will get the go package dependencies, run the unit tests, build the application for linux then wrap everything nicely up into a Docker image. - Run the functional tests
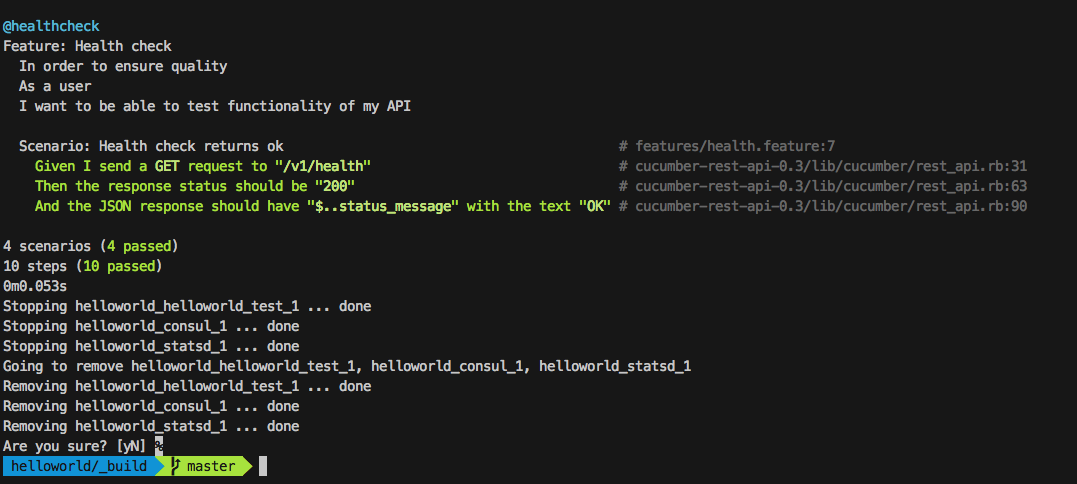
rake app:cucumberto spin up our mock environment using Docker Compose and execute the Cucumber tests against it. All things well you would see the following output from the terminal, if something did not work it will most likely be because you have not got your dependencies like Docker installed or set up correctly.
Consul
To feed config to our service we will use consul and consul template, the consul template can be found in _build/dockerfile/[servicename]/config.ctmpl. Consul template runs as a service in the container and checks for changes in Consul server. It will write the value that corresponds to the key and restart the server when a change is detected. The config itself is stored in a yaml file consul_keys.yml which Minke loads into consul on the start of the tests or when you run the application. Below is a simple example of a Consul template for our service, Consul is written in Go and the templates are actually Go templates.
{
"stats_d_server": "{ {key "app/stats_d_server"} }"
}
Docker Container
Ah Docker, the thing pay rises are made from, I love Docker, in fact I loath to use anything else for packaging and running an application these days. With the rise of services like Docker Cloud, Amazon Container Service and Google Container Service, long gone are the days of fighting with Chef and all things Unix which I have never fully understood. Docker is also just about perfect, no essential if you are building a microservice architecture, the pain it causes will be an order of magnitude lower than not using it.
Minke builds your code and wraps it up in a nice warm Docker blankie, check out the _build/dockerfile/[servicename]/ for more details but the dockerfile that go-microservice-template creates is based on Alpine linux which creates a nice small image, you can read more about that part of the process in another post here: http://nicholasjackson.github.io/other/micro-docker-images-for-microservices/.
Docker Compose
When you run or test your application Minke uses Docker Compose, if you examine the compose file in the build folder, you will see entries for consul and our StatsD server. As my service grows in complexity so does this file, in order to control behavior from dependencies when I am testing my code I generally use mock servers like Mimic. I try keep real dependencies like databases or queues to a minimum, as a rule of thumb on how micro is micro I would suggest that if you need to connect to more than one datastore your service might be two big. All other connections should be to other services which can be mocked.
version: '2'
services:
helloworld_test:
image: helloworld
ports:
- "::8001"
environment:
- "CONSUL=consul:8500"
links:
- consul:consul
- statsd:statsd
consul:
image: progrium/consul
ports:
- "::8500"
hostname: node1
command: "-server -bootstrap -ui-dir /ui"
statsd:
image: hopsoft/graphite-statsd
ports:
- "::80"
expose:
- "8125/udp"
environment:
- "SERVICE_NAME=statsd"
registrator:
image: 'gliderlabs/registrator:latest'
links:
- consul:consul
command: '-internal -tags=dev consul://consul:8500'
volumes:
- '/var/run/docker.sock:/tmp/docker.sock'
CI/CD
Sprint 0 get helloworld running under ci and deploying to an environment, I mentioned this earlier but I can not stress how much it will save your ass to keep your CI pipeline healthy, I have recently switched to CircleCI as they are capable of building both iOS and Android as well as my microservices. To get a Go based microservice running on CircleCI took a little wrangling at first as whilst the auto-detection and build process is nice it does not allow for Minke to do its magic. It is simple enough to configure to run the way we want as the below config shows.
To get your service building all you need to do is change the paths in the dependencies section to point to your namespace and project name. I have much love for CircleCI right now my builds take about 4 minutes for a service and most of that is setting up the environment, the UI is nice and clean and easy to use and the ability to SSH into the build host was absolutely essential when I was trying to figure out this config.
CircleCI Config
machine:
pre:
- curl -sSL https://s3.amazonaws.com/circle-downloads/install-circleci-docker.sh | bash -s -- 1.10.0
- sudo rm /usr/local/bin/docker-compose
- sudo curl -L https://github.com/docker/compose/releases/download/1.7.1/docker-compose-`uname -s`-`uname -m` > docker-compose
- sudo mv docker-compose /usr/local/bin/
- chmod +x /usr/local/bin/docker-compose
ruby:
version: 2.3.1
services:
- docker
environment:
GOPATH: /home/ubuntu/go
dependencies:
override:
- cd _build && bundle && bundle update
- mkdir -p /home/ubuntu/go/src/github.com/nicholasjackson
- cp -R /home/ubuntu/helloworld /home/ubuntu/go/src/github.com/nicholasjackson/
test:
override:
- cd /home/ubuntu/go/src/github.com/nicholasjackson/helloworld/_build && rake app:build_image && rake app:cucumber
Conclusion
Thats it we are done, 0 to microservice in 5 minutes, following the simple steps:
- Scaffold a new service (go run generate.go)
- Run the build script (rake app:build_image)
- Run the tests (rake app:cucumber)
- Create the circle.yml config
- Tell CircleCI to watch your project
- Push the code to your repo
- Boil the kettle and sit back and wait for the build to go green
For me this will always be work in progress and as I learn more I will update both Minke and minke-generator-go but for now this pattern is really working for me. If you have any comments please feel free to ping me a message, find a bug, always happy for contributions.
In the next post I am going to write more in-depth about service discovery and some software patterns for managing disconnected services.
Source Code
If you need it please check out the example project at https://github.com/nicholasjackson/helloworld.
Dependencies
Stuff to install or nothing will work and you will swear at me.
- Ruby https://rvm.io/
- Go https://golang.org/
- Docker Toolbox including Docker Compose https://www.docker.com/products/docker-toolbox
- CircleCI https://circleci.com/